
What Is Relationship Extraction about?
Relationship Extraction is about identifying the semantic relationships between entities (e.g., person, organizations, places) that are expressed in unstructured text. Relationship extraction extracts, for instance, information about a person’s place of birth, nationality, spouse, etc. or a company’s founder, headquarters, key executives, and so on.
While basic entity extraction identifies only named entities, relationship extraction identifies the connections among those entities, enabling a far deeper and richer knowledge discovery.
One common use case of relationship extraction is to compile structured biographical profiles from texts. An example of a structured biographical profile would be a Wikipedia-style infobox, as illustrated below for Paul McCartney and Apple:
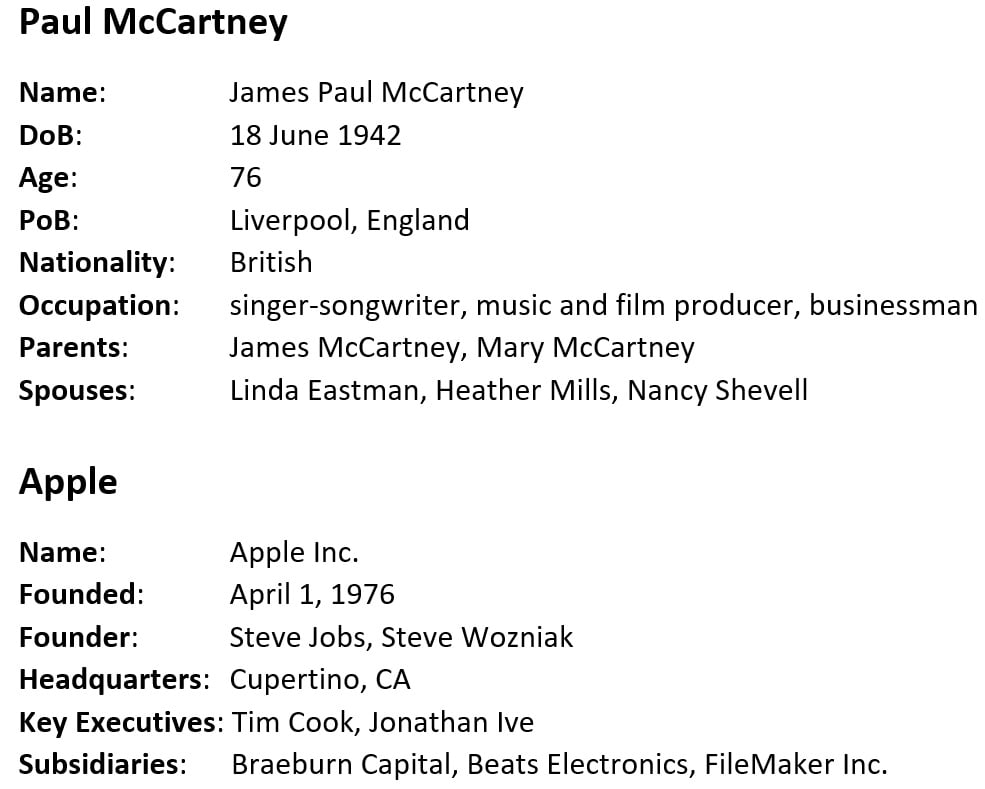
Without relationship extraction you would need to compile all this by hand. Relationship extraction makes the collection of such information on a large scale possible.
Why Is Relationship Extraction Challenging?
Relationship extraction comes with its unique set of challenges beyond extracting named entities accurately:
- One of the main challenges is that language can convey the same information in many different lexical and syntactic ways:
“Apple’s latest acquisition Beats Electronics”
“Apple’s subsidiary Beats Electronics”
“Beats Electronics, an Apple subsidiary”
“Beat Electronics will be Apple’s next acquisition”
Relationship extraction processes all of these quite different sentences and produces the same organization-subsidiary relationship between Apple and Beats Electronics.
- Another challenge for relationship extraction is coreference resolution, which is a complex cross-sentence analysis needed to figure out what entity pronouns and noun phrases refer to. For instance:
“Apple is on an acquisition spree. Under a deal announced this morning Beats Electronics will become its latest subsidiary.”
Here the subsidiary relationship is mediated by the pronoun “its.” Relationship extraction needs to figure out that “its” refers back to “Apple” in order to capture this relationship.
How Does Relationship Extraction Work?
A relationship extraction capability that is limited to finding just co-occurring or syntactically-related entities within a sentence would not be very useful because it does not tell the semantic relationship the two entities have. Also, such basic type of relationship extraction produces high rates of false positives and false negatives.
Instead, relationship extraction must be driven from a relationship ontology. A relationship ontology provides pre-defined semantic relationships for each type of entity. For example, a person entity may have, among others, the following relationships: age, place of birth, nationality, spouse, associate, and affiliation. An organization entity may have the following: founder, headquarters, affiliated person, subsidiary, and parent org. Each relationship has a semantic type and participants labelled according to the role they play in the relationship (e.g., a subsidiary relationship consists of a parent org and a child org).
Once the relationship ontology is defined, an NLP-based text analysis is performed to be able to derive semantic information from text. It involves identifying various building blocks such as named entities, phrases (e.g., noun phrases, verb phrases), and syntactic relationships (e.g., subjects, objects). Once those are identified, relationship extraction is able to detect relevant relationships in text, disambiguating and assigning their semantic type from its relationship ontology, and finding the relationship participants. When relationship participants are expressed via pronouns or definite noun phrases, coreference resolution comes in to find which named entities they refer to.
Since natural language can express the same concept in many different ways, the power of relationship extraction is that it can identify relationships of interest and produce a normalized structured representation from large volumes of unstructured text, thus going from rich unstructured text to structured information that can be exploited by downstream applications for structured biographical profile generation, link analysis, risk management, etc.
What Is Relationship Extraction Used for?
Relationship extraction is typically used for knowledge discovery from massive volumes of unstructured text, where timely manual analysis is simply not feasible or cost effective.
Relationship extraction is mainly used for two types of use cases:
- Compilation of structured biographical profiles. Manually compiling such information from a large volume of text data would be a very tedious and time-consuming process. Relationship extraction is thus critical for building entity-centered databases for solutions such as business intelligence (e.g., competitive analysis) and intelligence analysis (e.g., compiling dossiers of bad actors).
- Link and network discovery. There are several business areas where discovery of an entity’s connection to another entity is crucial.
- Risk Management. In the financial industry, it is important to identify the associates of certain potential customers as part of due diligence and KYC, for instance, to prevent getting associated with criminal activities and the risk of reputational damage. Applying relationship extraction to up-to-date text data regularly, such links can be discovered automatically and in a timely manner. Once an entity’s direct associates are found, relationship extraction can also be applied to these direct associates, thus initiating a sort of “six degrees of Kevin Bacon” analysis.
- National Security, where it is critical to monitor a web of links among the individuals who form adversarial groups to the nation. A previously unknown associate of a bad actor could be automatically extracted from a very large amount of documents and be displayed automatically in a link analysis tool for an analyst.
- Law Enforcement, where an analyst investigating a crime can be alerted to a connection to a seemingly unrelated crime such as the victims sharing a common address in the past.
- E-discovery. Relationship extraction enables legal teams to quickly uncover relationships (e.g., business associates, kinship relationships, company affiliations) hidden among millions of documents, thus significantly reducing the manual review time and costs associated with investigations.
Often organizations use link analysis tools, but analyzing unstructured data traditionally depends heavily on human analysts manually identifying relationships in texts. When the volume of the texts is big, manual analysis can become nearly impossible. Relationship extraction can help the human analysts with automatic extraction of relevant relationships from texts and allow them to focus on actual analysis and knowledge discovery.
Summary
Relationship Extraction is an AI technology of critical importance to many organizations that need to analyze very large volumes of unstructured text data in order to accomplish their missions, from biographical profiles to link and network discovery.




