Call us at (800) 511-6398
Contact us and see what NetOwl can do for you!
Entity Extraction, Homeland Security, Intelligence Analysis, Risk Management

Entity Extraction is a great way to automatically analyze and exploit a massive amount of text data, but have you ever wished the software could find more information than just named entities? More detailed information about these people and companies would be extremely useful! This is where Relationship Extraction comes in. For example, Relationship Extraction can discover the latest information about a person (such as their date of birth, place of birth, nationality, spouse, etc.) or a company (for example, founder, headquarters, key executives, etc.).
Biographical information is quite common across the Internet. An example would be Wikipedia’s infoboxes. Here’s some sample biographical information for Paul McCartney and Apple:
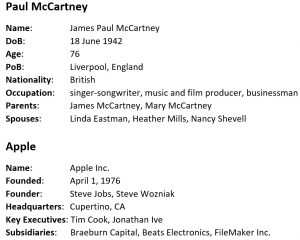
Without Relationship Extraction you would need to compile all this by hand. Relationship Extraction makes the collection of such information on a large scale quite possible.
Relationship Extraction identifies and disambiguates semantic relationships between two entities in unstructured text data. The entities may be expressed as named entities (extracted by Entity Extraction) or as regular noun phrases or pronouns (e.g., “The president was born in Scranton, PA.” or “It is headquartered in Paris.”).
What drives Relationship Extraction is a relationship ontology. A relationship ontology provides pre-defined semantic relationships for each type of entity. For example, a person entity might have, among others, the following relationships: age, place of birth, nationality, spouse, and associate. Organization entities might have the following: founder, headquarters, affiliated person, subsidiary, and others. Since each relationship has a semantic meaning, Relationship Extraction cannot be just limited to finding co-occurring or syntactically-related entities within a sentence. If there is a relationship between two companies, for example, Relationship Extraction must identify what the semantic relationship type is (e.g., subsidiary) and what role each entity plays (e.g., parent vs. child org).
Relationship Extraction has to deal with challenges of human language. One of the main ones is that language can convey the same information in many different syntactic and semantic ways:
“Paul McCartney was born on 18 June 1942 in Liverpool, England.”
“Paul McCartney’s birth occurred on 18 June 1942 in Liverpool, England.”
“Paul McCartney’s mother gave birth to him on 18 June 1942 in Liverpool, England.”
“Paul McCartney came into this world on 18 June 1942 in Liverpool, England.”
Relationship Extraction processes all of these quite different sentences and produces the same Place of Birth relationship between Paul McCartney and Liverpool, England, as well as the same Date of Birth information.
Another challenge for Relationship Extraction is handling pronouns:
“Paul McCartney was born on 18 June 1942 in Walton Hospital, Liverpool, England, where his mother, Mary Patricia (née Mohin), had qualified to practise as a nurse.”
Here the parental relationship is mediated by the pronoun “his.” Relationship Extraction needs to figure out that “his” refers back to “Paul McCartney” in order to capture this relationship.
Relationship Extraction is of critical importance to many organizations that need to analyze Big Text Data in order to accomplish their missions. Often these organizations use link analysis tools, but when analyzing unstructured data, this usually depends heavily on human analysts manually identifying relationships in texts. When the volume of the texts is big, manual annotation could become nearly impossible. Relationship Extraction can help the human analysts with automatic annotation of relevant relationships from texts and allow them to focus on actual analysis and knowledge discovery.
Examples of applications include:
In sum, Relationship Extraction is an exciting and effective technology that makes possible the establishing of extensive networks of links derived from very large amounts of unstructured text.

March 03, 2026

February 26, 2026

January 30, 2026